AWS Data Lake House Architecture with the Agile Cloud Manager
This is the second in our data lake house architecture series. This video and article describe AWS-specific architecture for data lake houses using Agile Cloud Manager.
The entire transcript of this video is given below the video so that you can read and consume it at your own pace. Screen shots of each slide are also given below to make it easier for you to connect the words with the pictures. We recommend that you both read and watch to make it easier to more completely grasp the material.
Agenda

This video will explain how an organization can become more Agile by decomposing the architecture of an AWS data lake house into its component parts, and then by placing each component of the Lake House under Agile product management using a free tool called the Agile Cloud Manager, which you can learn about at the AgileCloudInstitute.io web site.
We will also explain the architecture of a free, and fully-functional example of a software-defined A.W.S. data lake house in the market place section of the AgileCloudInstitute.io web site.
The same kinds of basic components of a data lake house exist in each type of cloud, but architecture of data lake houses is subtly different in each of the various cloud providers.
This video will discuss architecture of the collection of AWS managed services which can be pieced together to form a data lake house.
To make this easier to learn, we have divided this video into seven small sections, which are listed as folows:
- SECTION ONE: First, we will define the problem that can be solved by the architecture that we will explain in this video.
- SECTION TWO: Second, we will summarize how our free tool, Agile Cloud Manager, can be used to solve the problem.
- SECTION THREE: Third, we will build up a picture of all the major components of an AWS data lake house.
- SECTION FOUR: Fourth, we will explain how you can examine each of the components of the data lake house in order to determine the most effective architecture.
- SECTION FIVE: Fifth, we will start to explain the free working example of a software-defined AWS data lake house, which you can download from the AgileCloudInstitute.io web site. In the fifth section, we will show you how we have decomposed the data lake house into a few high level systems.
- SECTION SIX: Sixth, we will describe how the subcomponents of each system in the example appliance interact with each other to serve the needs of specific user groups.
- SECTION SEVEN: Seventh, and finally, we will discuss some of the next steps you can take after this architectural introduction.
SECTION 1: Problem Definition

Let’s begin with part one, the problem definition.
A common problem is that the extreme complexity of data lake houses can make it difficult for business stakeholders to drive the evolution of the enterprise’s data platform.
If the data lake house becomes too complex to explain, the lack of adequate explanation can cause data scientists to become less accountable to business stakeholders. This lack of adequate accountability can be very dangerous in an era in which data science and artificial intelligence are changing the shape of many industries.
A data lake house can become a monolithic mess that is difficult to evolve if the data lake house is not designed in an Agile way. A monolithic mess can hold the organization back at a time when the organization needs to innovate quickly.
We must prevent a monolithic mess, so that business stakeholders can be in a position to drive data- and A.I.- innovation.
SECTION 2: How Agile Cloud Manager Solves The Problem

Now, in part two, let’s look at how Agile Cloud Manager solves this problem.
There are at least three specific ways in which Agile Cloud Manager makes it easier to drive innovation in data lake houses.
Agile Cloud Manager’s domain-specific language makes it easy for you to create reusable, software-defined components of data lake houses. You can design each component to accomplish specific business goals for specific parts of your business. This means that you can actually model your business as a collection of cloud objects which each perform meaningful business-level functions.
Agile Cloud Manager’s command line interface C.L.I. makes it easy to deploy the business-level functional components of your data lake house. Easier deployments means easier evolution, so that your data lake house can evolve to meet business-level requirements more quickly.
Also, you can eliminate a LOT of redundant pipeline code. Because each one-line C.L.I. command does the work of what would otherwise be huge quantities of pipeline code. Less pipeline code makes it a lot easier to maintain systems defined with Agile Cloud Manager.
Agile product management can also be applied to each of the business-level components that you can define using Agile Cloud Manager’s domain specific language.
Agile product management can enable business stakeholders to more easily drive the evolution of your data lake house. This means that you can create an agile product backlog for each of the major components of your data lake house. Agile Cloud Manager’s domain specific language makes it easy for an architect and a product manager to translate specific feedback from users into specific changes to specific aspects of the data lake house that have meaningful value to the business. And the Agile Cloud Manager can make it easy for you to deploy those changes quickly.
SECTION 3: Components Of An AWS Data Lake House
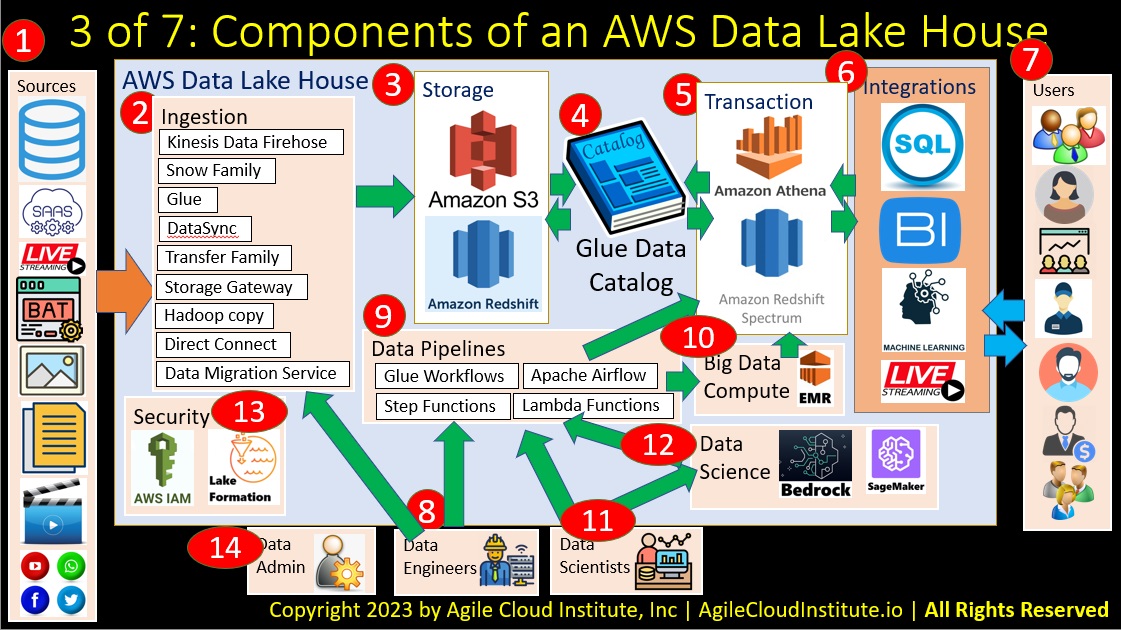
Here in part three, Let’s build up an AWS data lake house architecture starting with an empty slide, and gradually adding each of 14 elements one at a time.
Each component of the data lake house will be clearly numbered, and we will only add one component at a time to reduce the complexity, so that the entire lake house can be easier to understand.
Let’s begin with the data sources, which you can see numbered 1 on the left-hand side of the slide.
Data sources for a data lake house include virtually every possible type of data that can be relevant to your business. This includes all types of data inside your organanization. And this also includes many types of data that are outside of your organization, but that are relevant to your organization.
- Databases are one example of data sources. Your organization might have hundreds, or even many thousands of databases, which are all being updated all the time, and which all might need to be copied into the data lake house on an ongoing basis.
- Software as a service providers are another example. If your organization uses software as a service providers like salesforce, then data from those software as a service providers will need to be ingested into your data lake house on an ongoing basis.
- Live streaming data in many different forms can be relevant. You might need G.P.S. data from your support and distribution network. Or you might have internet of things appliances in many geographic locations streaming data back all the time.
- Batch files from legacy systems like mainframe systems might need to be ingested.
- Image data of many types might have relevance. One example of image data might be handwritten notes that physicians might write about patients and then fax in to an automated system that might use machine learning to read and interpret the handwritten notes.
- Textual documents of many types might contain relevant information that could be ingested into the data lake house.
- Video data from machine vision systems might contain meaningful business information.
- Social media sites might also be producing an ongoing flow of relevant data.
Many other types of data sources in addition to these might need to be ingested into your data lake house.
Next, the ingestion layer of the data lake house is shown with 2 as its number in red in the slide. Many different types of tools are available for data ingestion. These include many third party tools and at least 9 A.W.S. managed services for data ingestion. We are listing the 9 major A.W.S. managed services for data ingestion here to illustrate that there are many options, but we will not discuss each of these managed services in this video in order to keep this video easy to understand for a variety of audiences.
Number 3 on the slide illustrates the storage layer.
A data lake house utilizes two primary types of storage, including blob storage and a data warehouse.
In A.W.S., the service that provides blob storage is called ess three, and the name of the data warehouse service is Redshift.
Together, the blob storage and the data warehouse are able to store all types of data including structured data, unstructured data, and semi-structured data.
Number 4 on the slide is the data catalog. In A.W.S., Glue is the name of the service that manages the data catalog. There should be one single data catalog that serves as the one central source of truth for your entire enterprise.
The data catalog not only lists all of the data in the data lake house. The data catalog also provides metadata about each of the types of data in the data lake house. Together, the data and metadata in the data catalog are what enable the data in the data lake house to be searchable.
Number 5 illustrates the transaction layer in the slide.
The transaction layer includes services that handle SQL queries. A.W.S. has two major services in this category. Athena is better suited for handling queries of blob storage. And Spectrum is better suited for handling queries of the data warehouse.
The transaction layer is what consuming applications interface with in order to use data that is stored in the data lake house.
Number 6 in the slide illustrates some of the types of integrations that can connect consuming applications to the data lake house.
- Most consuming applications will run SQL queries to retrieve data from the lake house.
- Business intelligence tools will also query the data lake house.
- Machine learning or artificial intelligence systems might rely on the data lake house for their ongoing work.
- Live streaming data services might also rely on live streaming data feeds from the data lake house.
Number 7 on the slide shows many different types of users of various types of applications that might use data from your data lake house.
Some examples of types of users might include:
- Executives.
- Sales people.
- Marketing people.
- Customer support people.
- Operations people.
- Finance people.
- Human resources people.
- And others.
Notice that we have not discussed the bottom of this slide yet.
Data needs to be transformed in the data lake house, and a lot of work has to be done to maintain the data lake house.
Let’s examine three types of people who do the work to create and evolve the data lake house.
Number 8 illustrates data engineers.
Data engineers are responsible for a number of things, beginning with ingestion of data into the data lake house.
Data engineers create and mantain data pipelines. Not only for data ingestion, but also for cleaning data, enriching data, and transforming data.
Data pipelines can be created using many different tools.
The four data pipeline tools that A.W.S. offers as managed services include:
- Glue Workflows.
- Step Functions.
- Apache Airflow.
- And Lambda Functions.
The data pipelines can use the transaction layer to query the data catalog directly.
But number 10 on the slide illustrates that big data compute clusters are sometimes required, because some data jobs are so huge that dedicated computer clusters must be used to perform the jobs.
A.W.S. offers E.M.R. as its managed service for big data computer clusters, including Spark clusters.
E.M.R. stands for Elastic Map Reduce. Many people are more familiar with the name Elastic Map Reduce.
Data scientists are number 11 in the diagram.
Data scientists interact directly with data pipeline tools.
But data scientists can also interact with data science tools, which are numbered 12 on the diagram.
A.W.S. offers two primary managed services for data scientists, including Sage Maker and Bedrock.
You could also deploy and host your own data science tools on A.W.S. using open source tools. But this video is focusing on managed services provided by A.W.S.
Number 13 illustrates security for the entire data lake house.
A.W.S. offers Lake Formation as an access-management tool specifically focused on data lake houses.
I.A.M. is also used for identity and access management for data lake houses.
If you begin working with the example data lake house appliance that we will describe in coming slides, you can see that Lake Formation is designed to optionally over-ride I.A.M. in some situations in which Lake Formation is able to make it a lot easier to manage the specific requirements of securing access to resources in a data lake house.
Finally on this slide, numer 14 illustrates the data lake administrator.
The administrator is responsible for implementing most of the data lake house. Not just security and user management. But also possibly deploying the entire data lake house to provide working environments for all of the other types of people illustrated on this diagram.
Let’s take a moment simply to look at this entire diagram.
Do you see how complex a data lake house can become?
We started with a blank, empty slide in the video.
Then we added one component at a time. We numbered each component. We were careful to discuss each component before adding the next component.
Hopefully, the slow, incremental building of this diagram has made it easier to understand.
But do you see how complex a data lake house can become?
You will need to simplify this by decomposing the data lake house into smaller components in order for your organization to put your data lake house under Agile management.
Agile Cloud Manager can make it a lot easier to decompose a data lake house into meaningful components that can more easily be put under Agile management.
The remaining slides in this video will explain how.
SECTION 4: Examine The Life Cycle Of Each Element Of Lake House
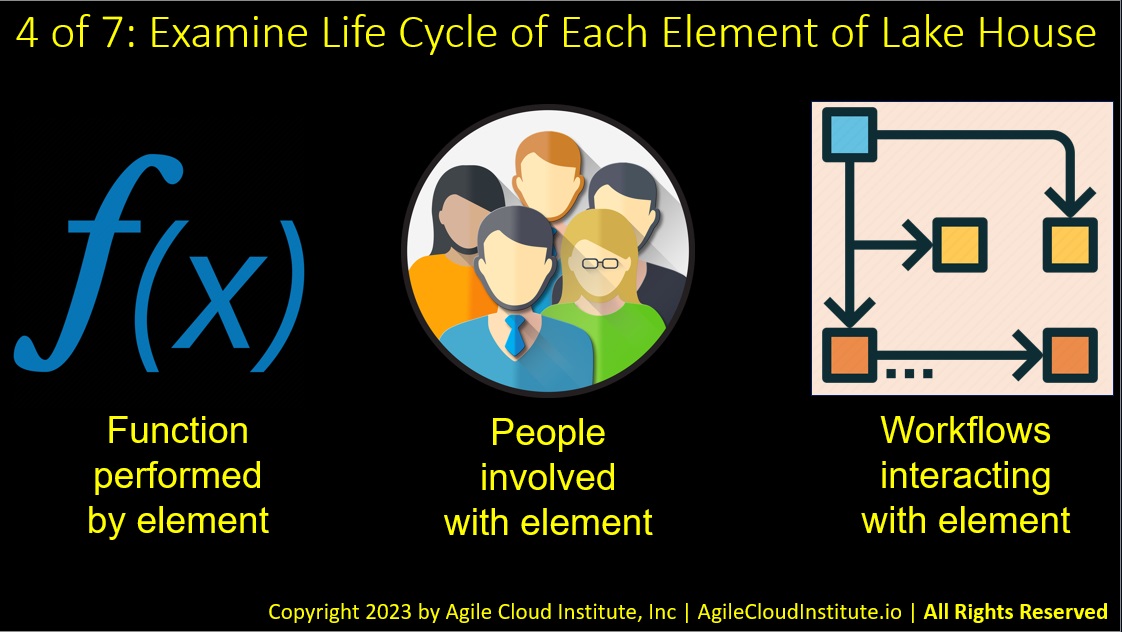
Here on the fourth slide, let’s start to simplify the complexity that was illustrated in the previous slide.
The best way to decompose the data lake house into meaningful components is to closely examine the life cycle of each element of the lake house.
This is a three step process.
- First, examine the function that is performed by each element of the lake house. This will tell you what each element of the lake house actually does.
- Second, examine the people who are involved with each element of the lake house. This involves looking at different types of people, and at the different requirements that people in different roles have for the data lake house.
- Third, examine the workflows that interact with each element of the data lake house. These workflows get triggered by specific things at specific points in larger processes. Each workflow has a number of different steps, and each of those steps performs specific functions. People are involved in most of the steps in each workflow.
After you have mapped out all of the functions, people, and workflows for each element of your data lake house, you will be able to see how the components can best be grouped into new Agile products.
Requirements gathering for each component will involve refining the function performed in order to better serve the people involved in specific workflows. The life cycle of each component will help you understand how often each component will need to be re-deployed.
Each new Agile product that you define should focus on serving specific types of people by improving specific functions within specific workflows. It will also help if deployments of each new Agile product can be done on a schedule that does not disrupt users.
SECTION 5: Systems In Example AWS Data Lake House Appliance
We have taken the liberty of creating a few example Agile products for you, so that it will be easier for you to begin decomposing a lake house into your own new Agile products.
We have also created a free working example of a software-defined AWS data lake house that you can download and begin working with right away to seed your AWS data lake house initiatives.
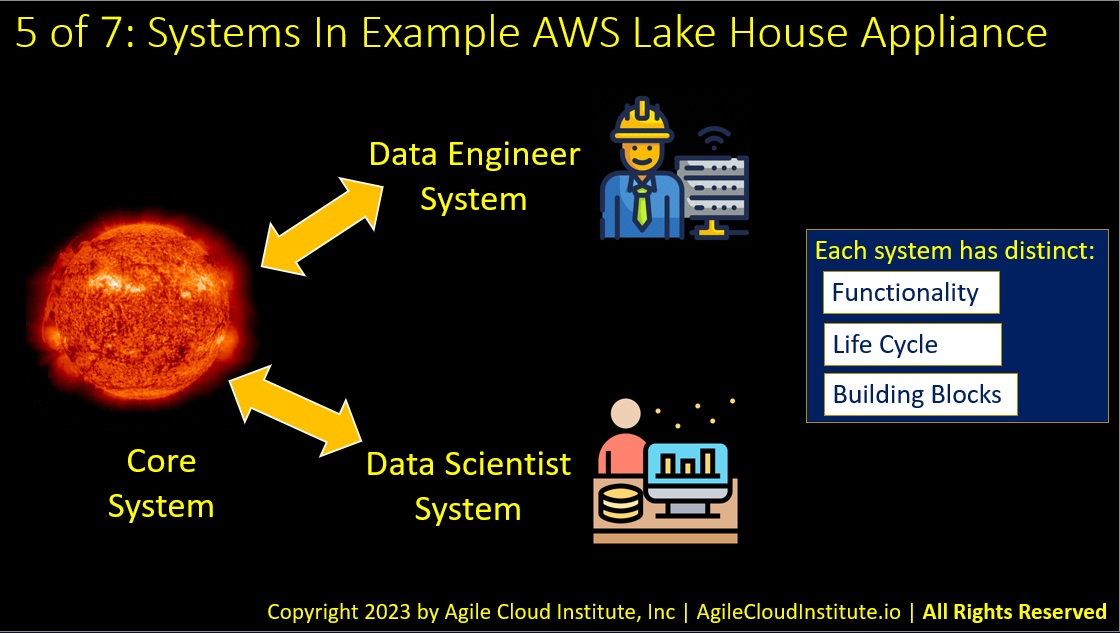
Our free working example of a software-defined AWS data lake house uses Agile Cloud Manager’s domain specific language to group elements of a data lake house into three distinct systems, and each of the systems can be easily deployed using Agile Cloud Manager’s simple command line interface.
The three systems in our free example AWS data lake house include:
- A core system that includes all of the resources that are shared by all users of the data lake house.
- A data engineer system that includes resources that are specific to data engineers.
- And a data scientist system that includes resources that are specific to data scientists.
Each one of these systems has distinct:
- Functionality.
- Life Cycle.
- Building Blocks.
You can re-arrange the elements of these systems any way you want. And you can create as many additional systems as you want.
But these systems are offered as example starting points. So that you can begin immediately with something that works out of the box. And so that you can solicit feedback from stakeholders earlier in your process without having to wait for a long development cycle.
The next few slides will take you through what is inside each of these example systems.
SECTION 6A: Core System Example Components
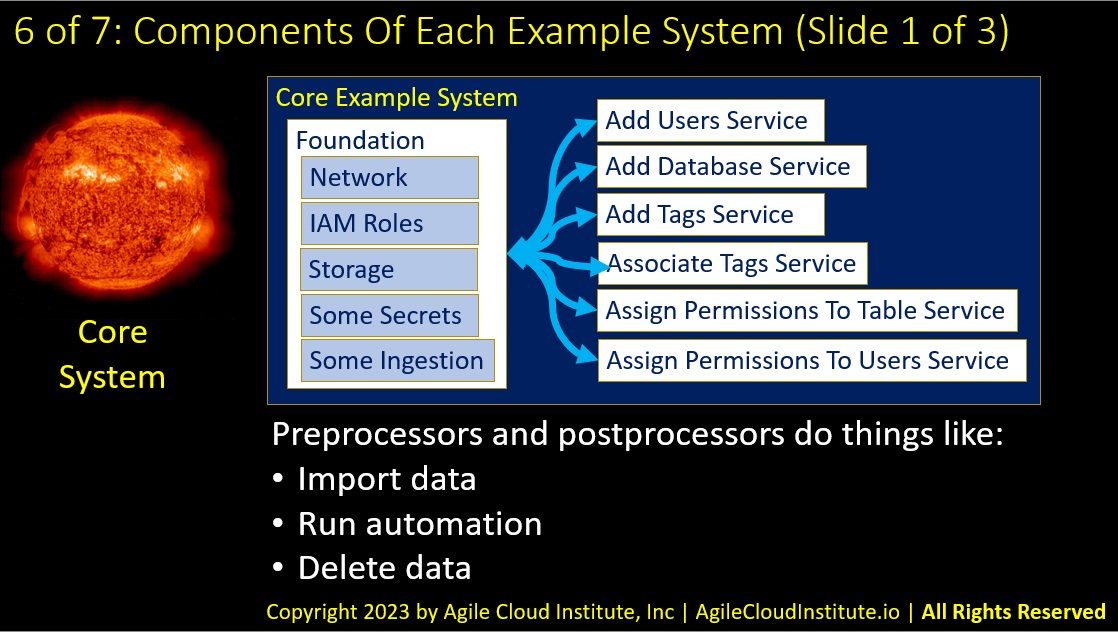
The core system is composed of a foundation and several different types of services.
The foundation contains things that are shared by the may types of services.
For example, the foundation of this particular example system includes:
- Networking.
- I.A.M. roles.
- Storage.
- Some secrets.
- Some ingestion of data.
The services in this example system each perform specific types of operations on things that were defined in the shared foundation. You can have as many types of services as you want, but the example services in this starter system:
- Add users to roles that were created in the foundation.
- Add a database.
- Add tags for use by other services.
- Associate tags with specific resources.
- Assign permissions to a table in a database.
- Assign permissions to users.
The services and the foundation are defined in whatever templating language you prefer. In this case, this example uses Cloud Formation templates underneath the Agile Cloud Manager’s system template.
You can also add your own scripts to each service or foundation, and your scripts can run either before or after the underlying templates.
Preprocessors are your scripts that you can run before running an underlying template.
Postprocessors are your scripts that you can run after running an underlying template.
Together, preprocessors and postprocessors enable you to do things like:
- Import data.
- Run other automation.
- Or delete data.
SECTION 6B: Data Engineer System Example Components
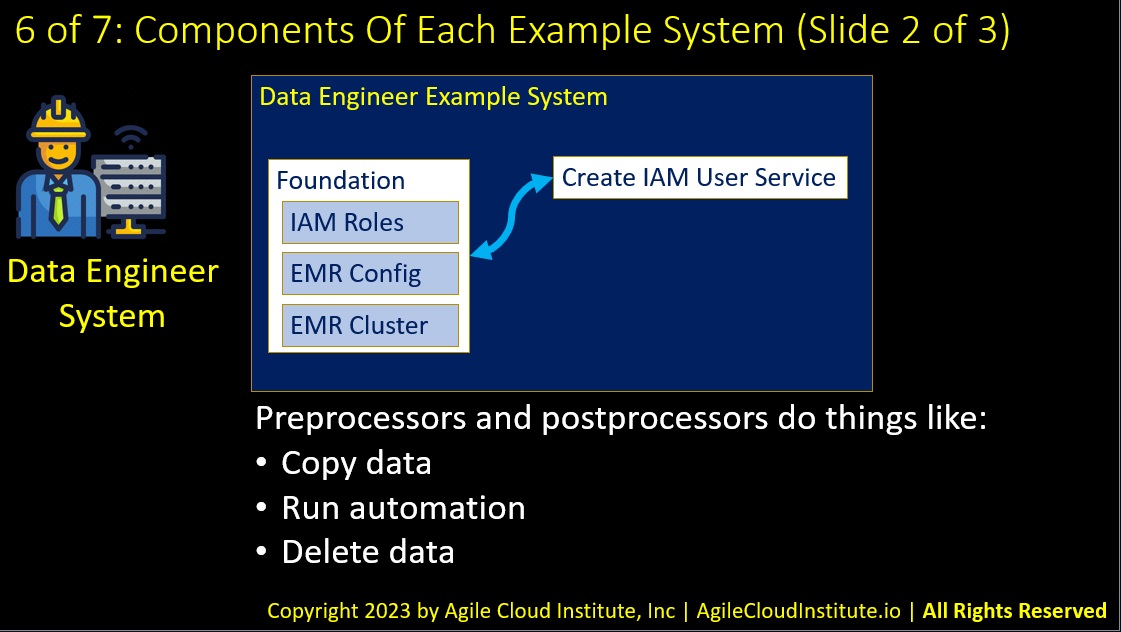
The data engineer system in our example AWS data lake house appliance interacts directly with the core system, but also has its own subcomponents.
The foundation in our example data engineer system includes:
- I.A.M. roles.
- Configuration for an E.M.R. cluster.
- And a dedicated E.M.R. cluster for data engineers to use.
The data engineer system also contains a service that creates I.A.M. users.
And there are also example preprocessors and postprocessors that do things like:
- Copy data.
- Run other automation.
- And delete data.
Of course, you can re-organize the elements of these example systems any way you want to.
For example, you might add a service that can create an E.M.R. cluster on demand at any time if you do not want to pay to always have a permanent E.M.R. cluster running.
The structure of your system definitions will depend on things like which job roles in your company own each task, and how often you want to deploy each component.
SECTION 6C: Data Scientist System Example Components

The data scientist system in our example is also a simple working starting point intended to seed your ideation process.
The foundation of our data scientest example system contains some shared storage for items that do not need to go into the data lake house’s central store.
There are two types of services in this example.
One service creates an E.M.R. cluster and a Sage Maker domain.
The other example service just creates a Sage Maker domain.
This example system also includes preprocessors and postprocessors that do things like:
- Copy data.
- Run automation.
- And delete data.
SECTION 7: Next Steps:
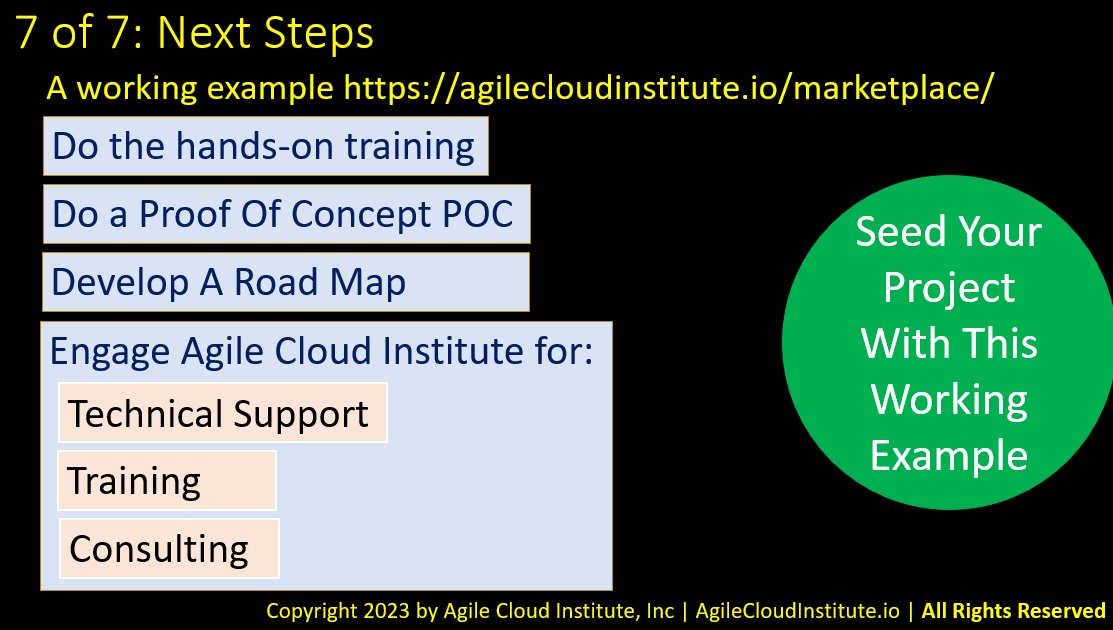
You can seed your data lake house initiative by using this working example to get something up and running right away on day one.
We offer hands-on training that you can use to get the data lake house running right away.
You can do a formal proof of concept by revising the architecture to fit your own requirements, and then by changing the free working example’s code to implement your own revised architecture.
You can also develop your own roadmap for all the other projects that can grow out of your proof of concept.
Agile Cloud Institute can help you with this journey.
You can hire Agile Cloud Institute to provide technical support, training, and consulting.
You can contact us through this web site, and you can connect with the architect of Agile Cloud Manager on LinkedIn. We would be happy to help you.