Agile AI Platform Architecture with the Agile Cloud Manager
Part 2 of 10: How AI Models Address Use Cases
The entire transcript of this video is given below the video so that you can read and consume it at your own pace. We recommend that you both read and watch to make it easier to more completely grasp the material.
SECTION TWO: How AI Models Address Use Cases
A.I. models are different than other types of applications.
A.I. use cases can be found in every aspect of an organization.
A.I. also requires a lot of data preprocessing that requires a modern data lake house, which we have described in other videos.
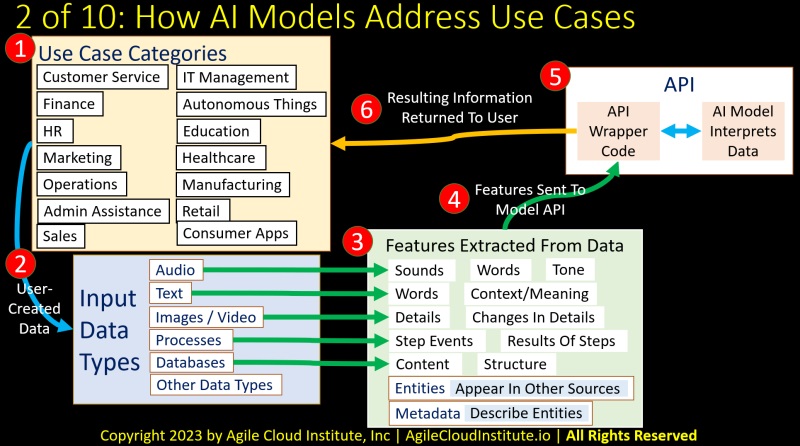
In this slide, let’s begin by discussing the use cases.
Number one on the slide lists some of the many types of use cases for A.I., including:
- Customer service tools for increasing customer satisfaction.
- Finance. For example, analyzing relationships between costs and profitability to identify ways to make the organization more profitable.
- Human resources. For example, analyzing employee activity in specific points in business processes to identify ways to increase employee satisfaction, and to thereby increase retention of employees.
- Marketing. For example, analyzing customer behavior to identify ways to increase customer engagement.
- Operations. Including tools that identify and take specific actions that can increase efficiency.
- Administrative assistance. For example, analyzing data to determine which people to send emails to, what to say to the people, and when to call the people.
- Sales. For example, analyzing the data in each step of the sales process and suggesting ways to optimize the sales process through specific actions recommended for specific people at specific points in the process.
- I.T. management. For example, analyzing systems and making changes to optimize performance.
- Autonomous things. Like self-driving cars. And self-driving machinery that automate tasks, like self-driving forklifts and self-driving mining equipment.
- Education. Including learning aids.
- Healthcare. Including managing patient data to recommend things that can result in better patient health outcomes.
- Manufacturing. For example, optimizing manufacturing processes.
- Retail. One example of a retail A.I. use case is to analyze video of customer activity in retail stores to identify situations in which a customer needs assistance in order to decide to buy a product. This kind of use case addresses the problem of customers leaving a store without having bought anything. An A.I. implementation can give store employees an opportunity to help customers decide to buy instead of leaving without having bought anything.
- Consumer applications for A.I. are many and diverse. Some examples include intelligent analysis of maps to recommend places for a person to visit, and intelligent analysis of exercise data to encourage a person to exercise more effectively.
Number two on the slide illustrates the data that is created by users when each of these many types of use cases for A.I. are implemented.
This is raw data that will need to be processed before it can be used by A.I. models.
Some of the many types of raw data created by users include:
- Audio data.
- Textual data.
- Images and video.
- Process data.
- Databases.
- And other data types.
Number three on the slide illustrates that features are extracted from the raw data before the data can enter any A.I. model.
Features are meaningful information that is hidden in the data until the data is analyzed.
Different types of data might contain different types of features.
For example:
- Audio data might contain different kinds of sounds that can be categorized. Or different words that can be identified and structured into sentences to derive meaning. And the tone of voices and other sounds can be characterized to further extract meaning from the situation that the audio data describes.
- Textual data contains words. And the words can be analyzed to identify the context and meaning of the words.
- Images and video contain details that can be characterized and identified. Changes in each detail might occur from image to image, and a summary of the changes in details might be a feature in the data that might be sent to an A.I. model.
- Process data includes features related to steps in the process. For example, different kinds of events might occur within each step. And different results might occur each time a step is completed in a process.
- Database data might be characterized by the content of the database, and by the structure of the database.
- Entities can also appear in any of the other types of data sources. One example of a type of entity might be specific people who might be identified by facial recognition or by voice recognition. Another example of a type of entity might be a motor vehicle that might be identified by image recognition of its license plate.
- Metadata is data that describes entities. For example, if feature extraction in data identifies a specific person, then the algorithms might attach metadata about the person before sending processed data to the A.I. model.
Let’s take a moment to look at input data types and feature extraction for a moment before moving further into this slide.
A modern data lake house is necessary in order to ingest data and extract features for use by machine learning models.
We have several videos about data lake house architecture at the AgileCloudInstitute.io web site.
The free example appliances that we will describe later in this video also enable you to create a working data lake house as part of an A.I. platform.
Data pipelines will ingest data and extract features from the data. Data engineers will develop and maintain the data pipelines that will take data to the point in the process that you can see by the end of number three on the slide.
Now let’s move on.
Number four in the slide shows how feature data is sent from the data lake house into an A.P.I.
Number five on the slide illustrates the A.P.I.
A.P.I. wrapper code receives the feature data and sends the feature data into the A.I. model.
The A.I. model then interprets the feature data and returns intelligent information back to the A.I. wrapper code.
Number six on the slide shows how the resulting information is then returned to the end user from the A.P.I.
We have abstracted away many of the details so that this diagram can be widely applicable.
Now take a step back and look at the entire slide for a moment.
Do you see how a wide variety of use cases for A.I. result in so much diverse data that a modern data lake house is required to ingest and process all the data?
And do you see how many diverse A.I. models can be required in many different microservices in order to serve all the many diverse use cases?
The enterprise data store can become vast, and requires centralized governance.
Almost every application in an enterprise might need to be rearchitected in order to more effectively leverage A.I.
These are very big requirements that need to be addressed at the enterprise architecture level before an enterprise can fully implement A.I.
In the next slide, we will examine another unique characteristic of A.I. models that requires significant changes in many organizations’ enterprise architecture.
Next: Proceed to Part 3: AI Models Break And Degrade Over Time
Back to Series Table Of Contents: Agile AI Platform Architecture With Agile Cloud Manager