Azure Data Lake House Architecture with the Agile Cloud Manager
This is the third in our data lake house architecture series. This video and article describe Azure-specific architecture for data lake houses using Agile Cloud Manager.
The entire transcript of this video is given below the video so that you can read and consume it at your own pace. Screen shots of each slide are also given below to make it easier for you to connect the words with the pictures. We recommend that you both read and watch to make it easier to more completely grasp the material.

The architecture of data lake houses can become a lot easier to manage when you use Agile Cloud Manager to define and deploy the components of a data lake house.
This video is the third in our series of data lake house videos.
The first video explained cloud-agnostic architecture of data lake houses using Agile Cloud Manager.
The second video explained AWS architecture of data lake houses using Agile Cloud Manager.
Now, this third video in the series will explain Azure architecture of data lake houses using Agile Cloud Manager.
We will also describe the architecture of a free working example of a software-defined Azure data lake house that you can download from the AgileCloudInstitute.io web site.
Agenda

This video is organized into six sections to make it easier to understand.
-
SECTION ONE: First, we will explain a common problem that companies experience with data lakehouses, and we will give a high-level summary of how Agile Cloud Manager can help to solve that problem.
-
SECTION TWO: Second, we will illustrate how a data lakehouse architecture can be assembled in Azure using Azure managed services. We will build up the architecture in organized groupings of components so that it can be easily understood, but you will see the need for a tool like Agile Cloud Manager that can greatly simplify the management of those components.
-
SECTION THREE: Third, we will explain an easy way that you can group the components of your data lakehouse into manageable sub-systems by examining the life cycle of each component.
-
SECTION FOUR: Fourth, we will give a high level summary of a free, working example of a software-defined data lakehouse appliance that you can download from AgileCloudInstitute.io and deploy to Azure to seed your own Agile data lakehouse project.
-
SECTION FIVE: Fifth, we will go a little deeper to show you what is inside each of the systems that we include in our free, software-defined data lakehouse appliance.
-
SECTION SIX: Sixth, and finally, we will describe some next steps that you can take to begin your Agile data lakehouse initiative in Azure starting with our free software-definition of a data lakehouse appliance at AgileCloudInstitute.io, which you can use to seed your efforts.
SECTION 1: Problem Definition And Solution
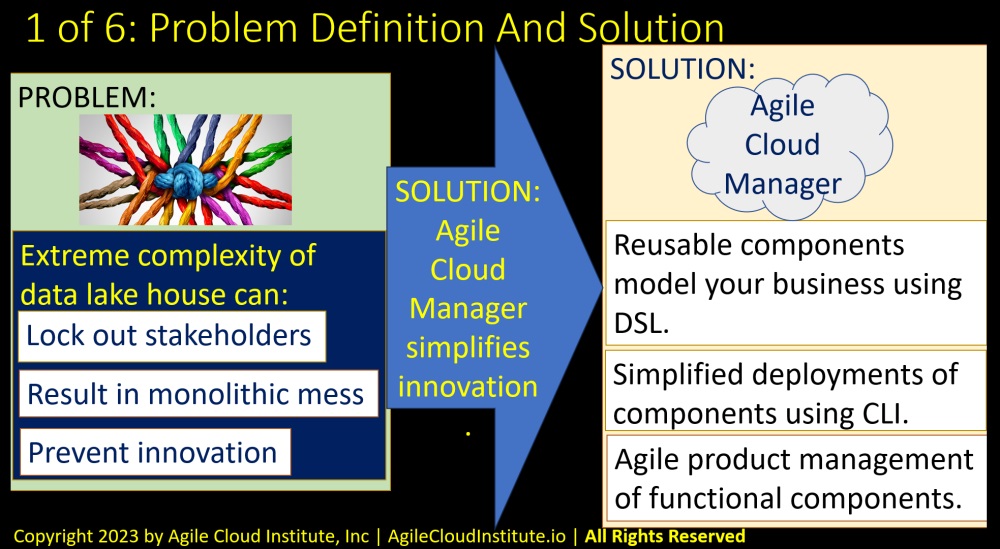
The problem that many organizations experience with data lakehouses has to do with managing complexity.
You will see in the next slide that a data lakehouse can become extremely complex because it includes so many different types of data that integrate so many different types of people, processes, and systems.
The problem is that the extreme complexity of a data lakehouse can:
- Lock out stakeholders because the lakehouse initiative is not easily organized in a form that lends itself to Agile product management.
- Result in a monolithic mess that is hard to manage and evolve.
- Prevent innovation because the elements of a data lakehouse are not naturally organized in a way that integrates with the enterprise’s project management processes as well as it could.
The solution to this problem involves simplifying the process of innovation in your data lakehouse’s overall structure.
Agile Cloud Manager can simplify the management of your data lakehouse in at least three main ways.
- First, Agile Cloud Manager’s domain specific language D.S.L. makes it easy for you to group the elements of a data lakehouse into reusable components that have meaning to your business.
- Second, Agile Cloud Manager’s command line interface C.L.I. makes it easy for you to deploy changes to each of the components that you can define using our domain specific language.
- Third, Agile Cloud Manager makes it easier to put each component of your data lakehouse into its own Agile product management program because the components are software-defined, and because the software definition allows deployment of changes to individual subcomponents.
Together, Agile Cloud Manager’s domain specific language, command line interface, and Agile prduct management can solve the common problems in data lakehouses so that your organization can leverage data to innovate more easily.
SECTION 2: Components Of An Azure Data Lake House
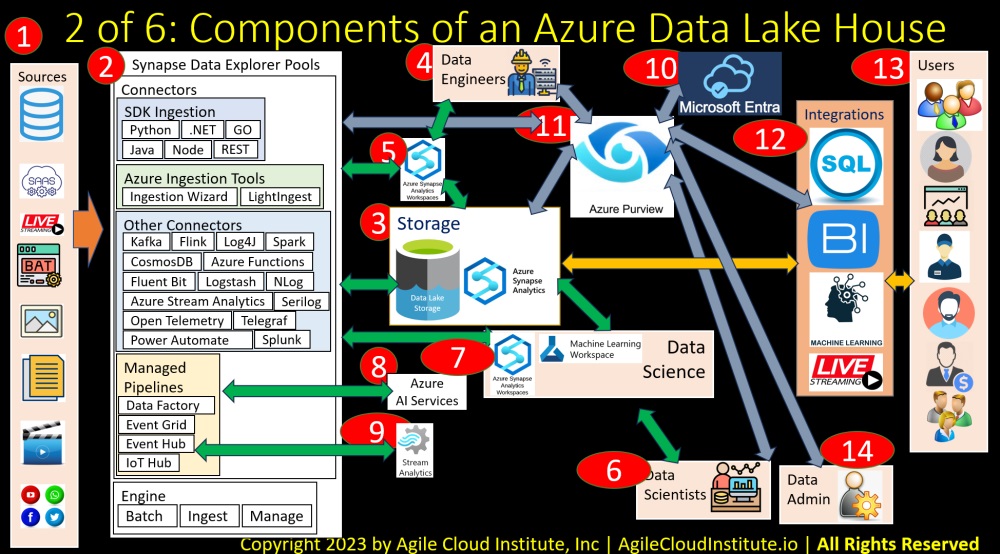
Now let’s build up a data lakehouse using Azure managed services.
We are beginning with an empty slide, so that you can see how the complexity builds up from easy-to-understand components.
Data Sources
First, let’s examine the data sources.
A data lakehouse will ingest all data that has relevance to the business. This includes data that is inside the business. But it also includes data that is outside of the business.
Some examples of the many types of data that a data lakehouse needs to ingest include the following:
- Databases of many types that are generated by many systems throughout your organization.
- Software as a Service providers. For example if you are using a C.R.M. service like Salesforce.
- Live streaming data sources of many types. This could include internet of things I.O.T. devices that your organization might have out in the field.
- Batch files from legacy systems such as mainframes.
- Image files. One example of image files might be handwritten documents that have been scanned and faxed. Such handwritten documents might be fed into natural language programming algorithms in order to extract meaningful information.
- Textual documents of many types, whose contents can also be pulled into algorithms for extraction of information.
- Video data. This might include security camera data, or other types of video that might benefit from analysis by vision algorithms.
- And social media data related to the business that is collected by social media platforms on an ongoing basis.
Synapse Data Explorer Pools
Number 2 on the slide illustrates Synapse Data Explorer Pools.
Azure Data Explorer is a service that enables you to ingest, operate on, and manage many different kinds of data.
Synapse is a tool that we will discuss in a little bit, after more of the elements have been added to this slide.
For now, just note that Synapse is going to spin up pools of Data Explorer instances that will perform the work of ingesting data into the data lakehouse and then transforming the data after data is ingested into the data lakehouse.
Storage Layer
Number three on the slide illustrates the storage layer of a data lakehouse.
In Azure, data lakehouse storage is placed in something called Azure Data Lake Storage, which is currently in generation two.
Azure data lake storage combines blob storage with database storage that is more commonly associated with data warehouses. So that the structured and unstructured data all get stored in the same place.
We are also putting Synapse in the storage layer in this diagram to illustrate that Azure data lake storage serves as a backend data source for Synapse.
But Synapse is largely a serverless tool that gets instantiated to perform specific work. So that it is more accurate to say that the long term data storage for a data lakehouse is done by Azure data lake storage.
To better understand Synapse, let’s look at some of the people who interact with the data in the data lakehouse.
Data Engineers
Number four in the diagram illustrates data engineers. The data engineers are the people in an enterprise who handle basic operations on data. Including data ingestion, basic data transformations, and data reporting.
Data engineers use Synapse in an Azure data lakehouse. Synapse acts as a serverless platform that spins up compute instances as necessary. So that your Synapse workspaces will only be active when you specify that work needs to be done. Synapse will also serve as a portal into all of the many other services that a data engineer will use in a data lakehouse. We will get to all those many other services in a little bit as this slide gets built up one element at a time for easier understanding. For now, just note that, if you are thinking about other data tools that a data engineer uses in Azure, those other tools can be used through a Synapse workspace.
Data Scientists
Number 5 on the slide illustrates data scientists. The data scientists use higher-level mathematics to develop machine learning and artificial intelligence models that can automate a lot of what the company does, including adding new services to a company’s offerings.
Data scientists use Azure Machine Learning Workspaces in addition to Synapse Workspaces. But there is an integration between Synapse and Azure Machine Learning Workspaces so that a data scientist can use Synapse to interact with an Azure Machine Learning Workspace in the same way that you will see that Synapse allows a user to interact with all of the Azure Data Explorer services that we will add to the slide in a few moments.
Synapse Data Explorer Pools Revisited
Number 2 on the slide, Synapse Data Exporer Pools, will make more sense now that we have described the storage layer, data engineers, data scientists, and the role that Synapse plays in integrating many diverse Azure services.
The data explorer engine is shown on the bottom.
The data explorer engine does things like batch data, ingest data, and manage data.
There are also many connectors that the data explorer engine uses to perform its work.
Some of the connectors enable software development kits, SDK, to do data ingestion work. We are listing some of the supported languages in this diagram, including Python, .Net, GO, and others.
There are connectors for Azure data ingestion tools, including Azure’s ingestion wizard and light ingest.
And there are other connectors for many other tools that are shown on the diagram including Kafka, Flink, Log four jay, Spark, and many others.
Several managed pipeline services can also be integrated with data explorer pools for Synapse. These include:
- Azure Data Factory.
- Event Grid.
- Event Hub.
- And IoT Hub.
Azure AI Services
Number 8 on the slide shows that Azure A.I. Services can be used through the managed pipelines. Azure A.I. Services is a collection of pre-built machine learning models that can be used by engineers who do not have a data science background. Azure A.I. Services make it easier for an organization to begin using A.I. without investing large amounts of capital to build teams of data scientists. And Azure A.I. Services can also be used by data scientists to perform basic tasks so that the data scientists can focus on things that are unique to the company.
Azure Stream Analytics
Number 9 on the slide illustrates that Azure Stream Analytics can be used by the streaming pipeline tools to perform operations on streaming data in real time.
Perspective On The Architecture Diagram So Far
Before we go any further, let’s take a big step back to consider how all of the elements that we have added to this slide so far interact with each other to form the foundation of a data lakehouse.
Most of the arrows have two directions.
The two-directional arrows indicate that all of the data will end up in the storage layer. This means that the things we will add to the right hand side of the slide in a few minutes will all be interacting through the storage layer. So that all of the operations performed by the data explorer pools will be available through the storage layer to the other users that we will add to the slide in a few minutes.
The two-directional arrows also show that data engineers and data scientists are using Synapse to use the many diverse Azure services which together operate on the data in the storage layer.
You can also start to consider that the storage layer itself is going to become partitioned into levels of readiness as a result of all the many operations that get performed on the data by the various elements that we have already added to this slide so far.
Raw data will be ingested into the storage layer.
The raw data will then be cleaned to be it easier to organize.
Then the raw data will be enriched by linking it with other data that provides more insights.
Both the raw data and the enriched data can be transformed to extract better information.
And data in various forms can be run through algorithms and machine learning models to feed business processes.
You can organize your storage layer into a series of partitions beginning with a raw data partition and ending in a gold partition that is ready for consumption by end users that we have not yet added to this slide.
The next two items that we will add to this slide relate to governing the data.
Entra
Number 10 on the slide is Entra.
Entra is the current generation of what used to be called Active Directory. Entra handles Identity and Access Management.
Purview
Purview is number 11 on the slide.
Purview is very important.
Purview performs some of the functions that a data catalog generally performs in a data lakehouse. But Purview is different than the Glue catalog that you see in A.W.S. Purview is also different from the Unity Catalog that you see in data bricks.
Purview is Microsoft’s central tool for governing all of the data in all locations anywhere in an enterprise, including the data lakehouse. We will limit our discussion to the data lakehouse in this video.
Purview integrates with many tools.
The grey arrows that we will add to the slide illustrate Purview’s integrations.
Purview integrates with Entra to track how users interact with data.
Purview integrates with data explorer to create an auditable record of every operation that gets performed on the data.
Purview integrates with the storage layer in terms of tagging each artifact in the storage layer with records of who has done what to each artifact at each point in time.
Purview’s integration with Synapse is shown through the arrow to the storage layer, and also through the arrows to the data engineers and the data scientists.
Some of Purview’s other integrations will be described as we add more items to this slide.
Integration Layer
Number 12 on the slide shows integrations that the end users of the data lakehouse will use in order to consume data from the data lakehouse. These integrations will be used by apps and systems. The end users will use the apps and systems that use these integrations.
Some of the types of integrations include:
- SQL queries.
- Business intelligence tools.
- Machine learning tools.
- And live streaming data tools.
Integrations interact both with Purview and with the storage layer.
The Purview catalog can be searched in order to identify metadata about any of the data in the data lakehouse.
So the Purview catalog can be used to provide a map of the data, which is part of the process of data discovery.
But then the data has to be queried directly, which is shown in the yellow arrow that connects the integrations in number 12 with the storage in number 3.
There are a number of different ways to directly query the data in the storage, but we are abstracting those ways into the yellow arrow to keep this slide in an easier-to understand form.
End Users
Number 13 on the slide illustrates the end users of data from the data lakehouse. These end users can include people in many different job functions, both inside your organization and also outside your organization.
Some examples of the various types of end users might include:
- Executives.
- Sales people.
- Marketing people.
- Customer support people.
- Operations people.
- Finance people.
- Human resources people.
All of these different types of people will have their own requirements for data.
The data lakehouse will need to be flexible enough to be able to evolve to meet the needs of all of the many different types of people.
Data Lake House Administrator
Finally on this slide, number 14 illustrates the data lakehouse administrator.
You can think of the data lakehouse administrator as the subject matter expert who is responsible for the systems administration tasks involved in managing day to day use of the data lakehouse. This includes things like user management. This might also include training of various types of users.
Most importantly, the data lake administrator might be responsible for deployment of changes to the data lakehouse platform in collaboration with the agile product managers and the architects.
Architectural Perspective About Entire Diagram
Take a look at this entire slide all together now.
Do you see how a data lakehouse can easily become a monolithic mess if an organization is not careful to design it in an Agile way?
All of the data relevant to the business can be put into the data lakehouse. So that the scale of the data lakehouse can grow to exceed what some people are used to comprehending.
Agile Cloud Manager provides a way to simplify the management of data lakehouses.
Let’s explore how in the next few slides.
SECTION 3: Examine The Life Cycle Of Each Element Of Lake House
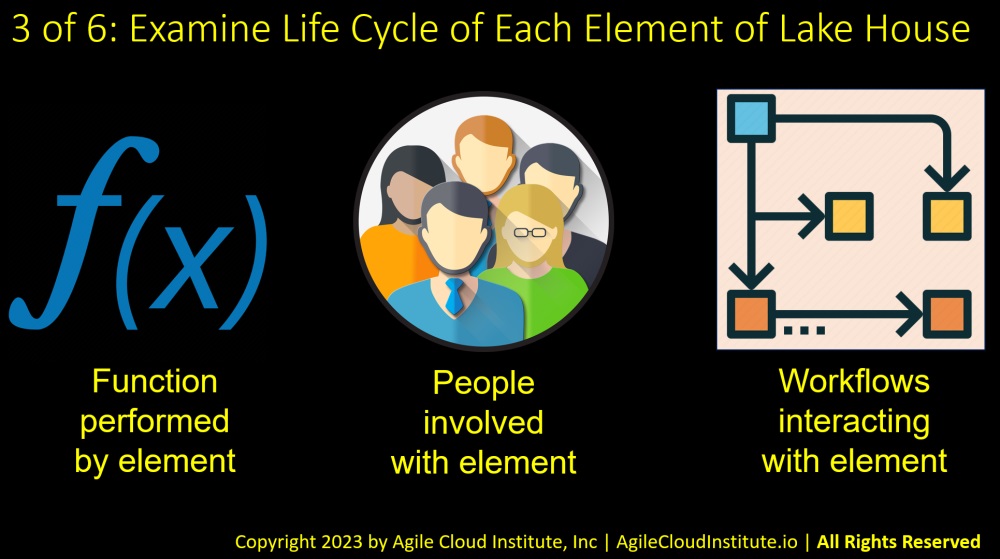
The way to decompose a data lake house into a set of manageable Agile products is to examine what happens during the life cycle of each component of the data lake house.
You can begin by listing all of the components of the data lake house, using the previous slide as a starting point for your list.
Then put the list into a table with four columns. The components of the data lake house will comprise the first column.
The second column is where you will write down the functions that are performed using each of the components of the data lake house.
The third column is where you can write down the people who are involved with each component of the data lake house.
And the fourth column is where you can write down the workflows that are involved in each component of the data lake house.
You can create supporting documents to elaborate upon what you summarize in the table. Supporting documents might describe each of the functions in more detail, and might document each of the workflows in detail. An architect and a product manager might actually interview the people involved in each component to create detailed sets of requirements for each component of the data lake house.
When you assemble all of the information described on this slide, you will be ready to start to define a set of Agile products, each with their own architectures and product backlogs.
SECTION 4: Systems In Example Azure Data Lake House Appliance
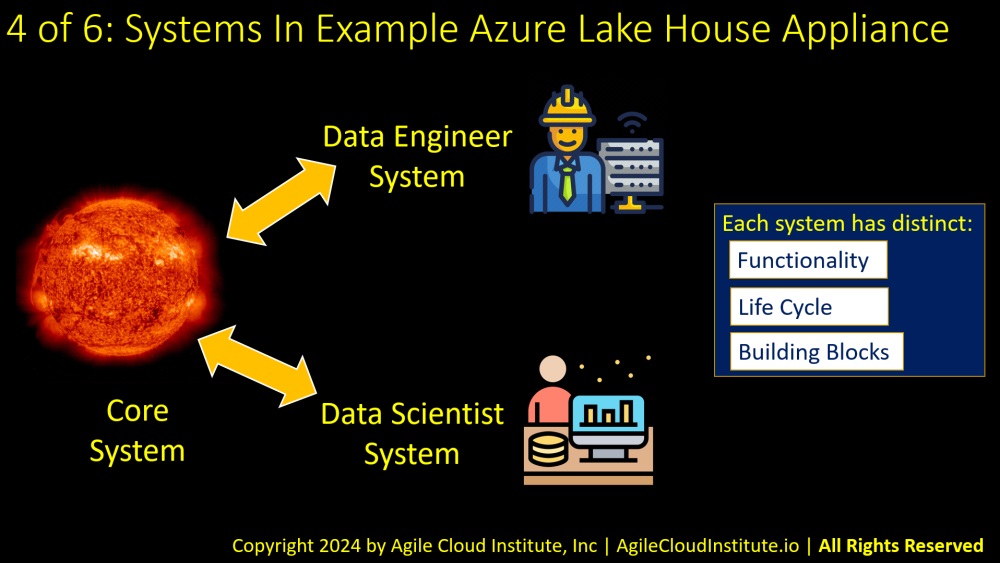
We have taken the initiative to create a working example of a software-defined data lake house in Azure for you.
Let’s look at how we have structured the example appliance.
There are three separate systems in our appliance, and each of the systems interacts with the others.
- A core system contains shared resources that are used by the other systems.
- A data engineer system contains resources specific to data engineer users.
- And a data scientist system contains resources that are used by data scientists.
Each of these systems has its own distinct:
- Functionality.
- Life cycle.
- And Building blocks.
These systems are defined in Agile Cloud Manager’s easy domain specific language DSL.
And the system templates in turn orchestrate lower level templates in other languages that you might already use. In this particular example, the system templates orchestrate Azure Resource Manager ARM templates that enable you to manage resources in Azure. So you can still use ARM templates, while Agile Cloud Manager provides a higher level of abstraction that allows you to manage your business more effectively.
The next three slides will describe what is inside each of these three sytems in our free example software-defined Azure data lake house appliance.
SECTION 5A: Core System Example Components

The core system in our example contains both shared resources and also resources that the data lake administrator might use.
There is a foundation in the core system example. Foundations are an optional part of a system in Agile Cloud Manager’s domain specific language.
The foundation in this example includes:
- a storage account with Azure Data Lake storage, and
- a Purview account that can be used to govern the data lake house.
There are several types of services that are included in the core system example. These include:
- A Synapse workspace service for the data lake administrator to use.
- A service that pauses Synapse at a specific time each day so that your organization does not have to pay for time it does not use.
- A service to resume Synapse at a specific time the next day so that the Synapse service is available when it is needed.
- And two services that each assign a role that authorizes the Pause and Resume services to do their assigned tasks.
There are also preprocessors and postprocessors in the example core system.
Preprocessors and postprocessors are scripts that you can specify to run before or after a cloud template is run.
In this example, the preprocessors and postprocessors do things like:
- Register the Purview service with your Azure subscription so that a Purview acount can be created.
- Remove the Purview service after the rest of the core system is destroyed, so that it does not remain after it is needed.
- And other types of administrative tasks that work around the limitations of whatever cloud scripting language you might be using.
SECTION 5B: Data Engineer System Example Components

The second system in our example data lake house appliance is a data engineer system.
This particular system does not include an optional foundation, though you could add a foundation yourself as you develop your own appliance starting from this example.
The services in this data engineer system include:
- A Synapse service designed for data engineers.
- A service that pauses Synapse at a specific time each day.
- A service that resumes Synapse at a specific earlier time the next day.
- And two services that add roles to authorize the Pause and Resume services to make the changes they are designed to make.
There are also preprocessors and postprocessors that do things like:
- Copy data.
- Run automation.
- And delete data.
SECTION 5C: Data Scientist System Example Components

The data scientist system in our example appliance contains a service that manages a machine learning workspace for data scientists to use.
There are also preprocessors and post processors that do things like:
- Delete the machine learning workspace before you run a delete command on the ARM template, so that the automation can override Azure’s rule that prevernts ARM templates from deleting machine learning workspaces.
- Purge a key vault so that the automation can run again and again without being blocked by Azure’s rule preventing ARM templates from purging key vaults.
- Other administrative tasks that you might specify.
Note that you can easily add services to manage a Synapse workspace for data scientists if you put any new Synapse into a different subscription.
This starter example is able to remain simple for you to use on day one because this example:
- Only requires one Azure subscription.
- And stays within the maximum of 2 Synapse workspaces per subscription that is default in Azure.
All three of these example systems are intended to be easy working starting points in a software-defined appliance that enable you to get working right away on day one.
You can make any changes that you want to these example systems.
SECTION 6: Next Steps
The next steps after watching this video are to begin working right away on a project that begins with a free working example appliance in the marketplace section of the AgileCloudInstitute.io web site.
You can seed your project with this working example.
You can do a proof of concept P.O.C. by building upon the free working example to meet the unique needs of your organization.
You can develop a roadmap for evolving your P.O.C. into a more full-featured data lake house that meets the needs of your enterprise.
And you can hire Agile Cloud Institute to perform:
- Technical support.
- Training.
- And Consulting.
You can contact us through the AgileCloudInstitute.io website contact form. And you can message the architect on LinkedIn to discuss these topics directly with the architect.
We would be happy to help you.